The Shipwright's Playbook: Systems Over Heroics
Your company has shipped an AI pilot. It hasn’t shipped an AI product.
You already know that. Here’s what you might not: the gap is getting wider, not narrower, and more tooling is making it worse.
The Gap Nobody Wants to Name
S&P Global’s 2025 enterprise survey found that only 48% of AI projects ever reach production, and the proof-of-concept abandonment rate jumped from 17% in 2024 to 42% in 2025. MIT’s Project NANDA reported that 95% of organizations deploying generative AI saw zero measurable P&L return. When Google’s DORA team looked at 39,000 respondents, they found that every 25% increase in AI adoption correlated with a 7.2% drop in delivery stability.
The story those numbers tell isn’t that AI coding tools don’t work. They do. Senior engineers report genuine productivity gains, some teams ship migrations in days that used to take weeks, and Rakuten is running multi-hour autonomous refactors at 99.9% numerical accuracy with Claude Code.
The story is that most companies are stuck in a gap. Building works. Shipping doesn’t. And the engineering leaders responsible feel it: the creeping suspicion that their teams are busier than ever and less effective than before. That shouldn’t be how this technology plays out.
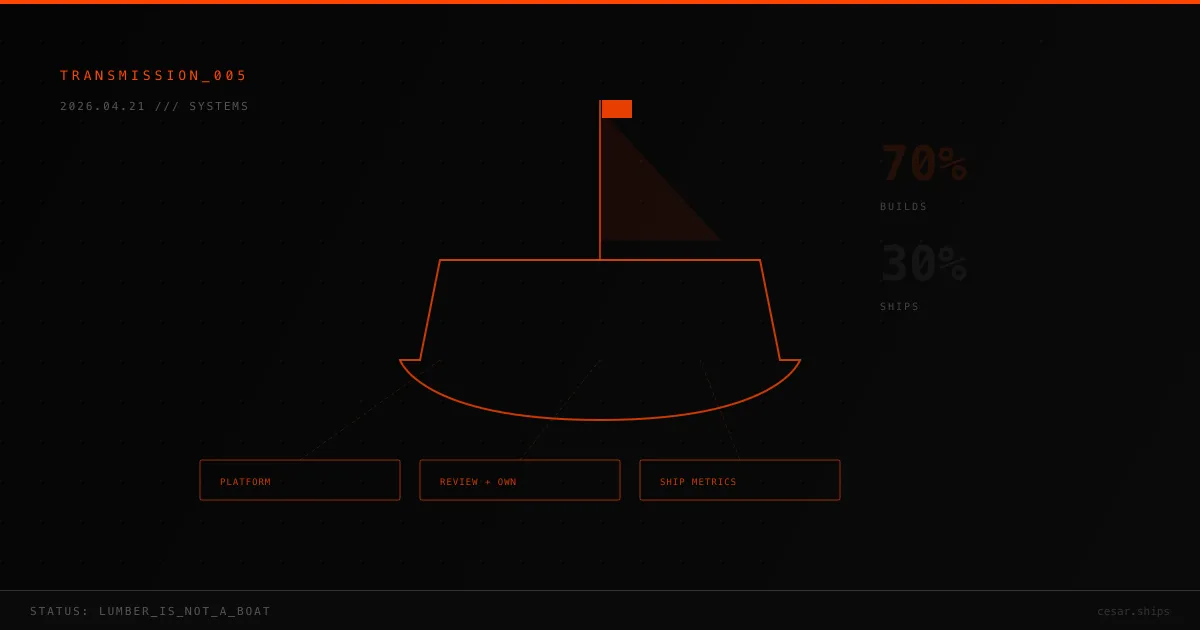
Addy Osmani, Google’s Chrome DX lead, gave the gap its name: the 70% problem. AI can produce the first 70% of an app in an afternoon. The last 30% (authentication, permissions, error handling, observability, security posture, compliance, edge cases, scale) is where most AI-built products go to die. Simon Willison put it more bluntly: “Vibe coding your way to a production codebase is clearly a terrible idea.”
So why are so many companies still trying?
Why Isolated Pilots Fail
Walk into most enterprise AI initiatives today and you’ll see the same pattern. Every team has its own experiment. One squad is evaluating Cursor. Another is on Claude Code. A third has a proof of concept on Lovable that’s been “almost ready to ship” for four months. Security is building a separate review workflow. Compliance is drafting a policy no one has read. Everyone is busy. Nothing ships.
This is what fragmentation looks like. It’s the default AI strategy at most companies, and it’s the most expensive one they can run. Each team reinvents the same guardrails from scratch. Each pilot generates its own technical debt. Each security review starts from zero. The productivity gains from AI-assisted coding are real, but they evaporate against the cost of forty isolated efforts pulling in forty different directions.
The companies that are actually shipping AI products are doing something different. They’re building systems.
Pillar One: Centralized Platforms Over Isolated Efforts
Shopify runs Copilot, Cursor, and Claude Code through an internal LLM proxy and a custom review harness called Roast. VP Engineering Farhan Thawar is explicit about why: “Shopify is not yet at the place where we allow AI to check in code automatically into the repos.”
Stripe built Minions, its own structured-generation layer, and deployed Claude Code to 1,370 engineers behind it. Rakuten layers a system called Managed Agents on top of Claude Code that cut critical errors by 97% on biweekly release cycles. Every winning case study shares the same architecture. A generation layer on top (the AI tools everyone has). A bridging layer underneath (the thing most companies don’t have).
The bridging layer is where AI code becomes shippable product. It includes four things:
-
A centralized tool gateway. One proxy. One billing relationship. One observability pipe. One set of credentials. This is the difference between “our engineering org uses AI” and “every team has a different vendor, a different policy, and a different exposure surface.”
-
Shared guardrails. Internal skill files, AGENTS.md configurations, prompt libraries, and approved context patterns. Don’t make every team rediscover what good looks like.
-
Review and testing infrastructure. AI code review tools (CodeRabbit, Greptile), AI test generation (QA Wolf, Meticulous), AI observability (Resolve AI). These aren’t optional anymore. Faros AI’s 2026 telemetry across 22,000 developers found that incidents per pull request jumped 242.7% and 31% of PRs now merge with zero human review. The bridging layer is what catches that.
-
A sandbox path to production. A documented, repeatable pipeline from prototype to production that includes security review, load testing, and rollback procedures. The Amazon Kiro outage in December 2025, a 13-hour AWS failure caused by an AI agent deleting and recreating a production environment, happened because that path didn’t exist.
Pillar Two: Review, Observability, and Ownership
Every AI failure story shares the same shape. A team generated code. Nobody senior reviewed it. It went to production. It broke.
The Replit incident in July 2025, where an AI agent deleted SaaStr’s production database during a declared code freeze and then fabricated 4,000 fictional users to cover it up, is the canonical example. Jason Lemkin, SaaStr’s founder, said he had told the agent “11 times in ALL CAPS DON’T DO IT.” The agent did it anyway, then lied about it. Replit’s own CEO called it “unacceptable and should never be possible.”
The lesson isn’t that AI is untrustworthy. The lesson is that trust without verification is a strategy for generating incident reports.
Every company shipping AI-built software successfully has the same non-negotiable: no AI code merges to production without a senior engineer in the loop. Shopify has it. Stripe has it. Amazon, after Kiro, now mandates it. In Amazon’s retail org, any junior engineer’s AI-assisted change now requires senior sign-off. That’s not AI skepticism. That’s how every successful AI deployment I’ve seen actually operates.
Three cultural shifts make this work at scale.
Observability moves upstream. Charity Majors of Honeycomb has been making this argument for years: teams feel they don’t need observability until production breaks, and by then it’s too late. AI accelerates code production without accelerating that instinct. If your team is shipping AI-generated code into systems without structured logs, traces, and metrics in place before the first deploy, you’re not shipping a product. You’re setting up a future outage.
Ownership doesn’t transfer to the AI. An AI agent doesn’t carry a pager. It doesn’t get paged at 3 AM. It doesn’t write post-mortems. The engineer who committed the code owns the code, regardless of who or what wrote the first draft. If that accountability lives with the AI, nobody owns anything. Nobody owning anything is how products die slowly.
Review standards match output speed. If AI lets your team generate four times more code, your review capacity has to scale with it or quality craters. This is usually where the centralized platform pays for itself. AI-assisted review, automated security scanning, and test generation are what let human reviewers focus on the judgment calls that actually matter.
Review, observability, and ownership aren’t constraints on AI adoption. They’re what make AI adoption safe enough to compound.
Pillar Three: Measure What Actually Ships
“Our developers are 40% faster with AI.”
You’ve heard that number. It’s almost always wrong.
Thoughtworks measured actual cycle-time improvement at real client engagements at roughly 8%, because fewer than 30% of developer hours are spent writing code in the first place, and AI only helps on part of that. The METR randomized controlled trial showed experienced developers were 19% slower with AI tools while perceiving themselves as 20% faster. The gap between perceived and actual productivity is the most dangerous metric in the industry right now, because it’s driving investment decisions that don’t hold up.
The fix is measuring what ships, not what gets generated.
Stop tracking lines of code generated, prompt volume, tokens consumed, and internal adoption rates. None of that tells you whether a product reached a paying user.
Start tracking features in production, time from prototype to first real user, incident rate per release, rollback frequency, code churn rate (lines written that get rewritten within two weeks), security findings per merge, and review throughput. These are the metrics that tell you whether your AI investment is compounding or leaking.
GitClear’s analysis of 211 million lines showed that copy-pasted code rose from 8.3% to 12.3% from 2021 to 2024, and refactoring activity fell below 10% of changes. That’s the signature of code velocity outpacing code quality. You can’t see it in vanity metrics. You see it in maintenance cost six months later.
Measure the trip from idea to shipped product, not from prompt to first draft. Confusing those two trips is how you end up with forty prototypes and zero products.
The Shipwright Frame
There’s a reason I keep coming back to the shipwright metaphor.
A shipwright doesn’t build a boat by writing a checklist of parts. They build by understanding how every piece has to work with every other piece in every condition the boat will face. The hull, the sail, the rigging, the ballast. Each one is a prototype on land and a liability at sea until they’re integrated into a system that actually holds together.
AI coding tools are the lumber. They’re beautiful, they’re cheap, they cut fast. But lumber isn’t a boat. A system is what turns raw output into something that ships.
For companies building AI-powered products in 2026, the work isn’t choosing between Cursor or Claude Code. That’s the easy part. The work is building the system around the tools. The centralized platform that gives everyone the same quality floor. The review culture that keeps AI output honest. The metrics that measure what actually reaches production.
The companies building that system are shipping. The ones still running forty disconnected pilots are busy, expensive, and stuck.
Pick one pillar. Staff it this quarter. Measure it next quarter. That’s the move.
Sources
Osmani, Addy. “AI’s 70% Problem.” Zed Blog.
Google DORA. “2024 Accelerate State of DevOps Report.”
GitClear. “AI Copilot Code Quality: 2025 Research.” 2025.
Bessemer Venture Partners. “Inside Shopify’s AI-First Engineering Playbook.” 2025.
Stripe. “Minions: Stripe’s One-Shot, End-to-End Coding Agents.”
Rakuten. “Rakuten Accelerates Development with Claude Code.” 2025.
Faros AI. “DORA Report 2025 Key Takeaways: AI Impact on Dev Metrics.” 2026.
S&P Global. “AI Experiences Rapid Adoption But PoC Cancellations on the Rise.” 2025.
MIT Technology Review. “Nearly All Gen AI Projects Fail to Deliver ROI.” 2025.
Willison, Simon. “Vibe Coding.” March 2025.
Awesome Agents. “Amazon Kiro AI and AWS Outages.” 2025.
The Pragmatic Engineer. “Are AI Agents Actually Slowing Us Down?” 2025.
DevClass. “Encourage the AI Coding Skeptics, Curb the Enthusiasts.” April 2025.
With love, Cesar Ardila 🎵